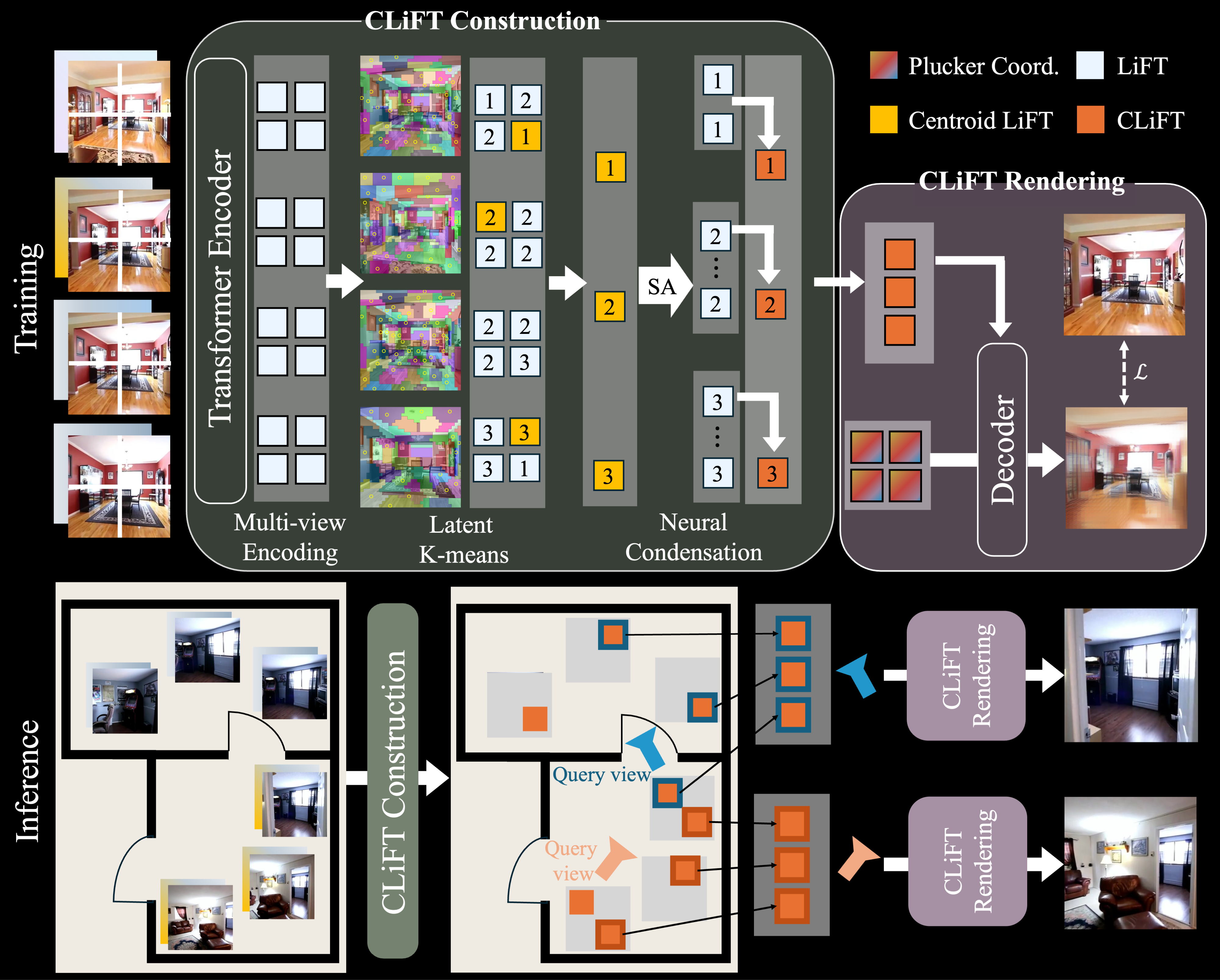
This paper proposes a neural rendering approach that represents a scene as "compressed light-field tokens (CLiFTs)", retaining rich appearance and geometric information of a scene. CLiFT enables compute-efficient rendering by compressed tokens, while being capable of changing the number of tokens to represent a scene or render a novel view with one trained network. Concretely, given a set of images, multi-view encoder tokenizes the images with the camera poses. Latent-space K-means selects a reduced set of rays as cluster centroids using the tokens. The multi-view "condenser" compresses the information of all the tokens into the centroid tokens to construct CLiFTs. At test time, given a target view and a compute budget (i.e., the number of CLiFTs), the system collects the specified number of nearby tokens and synthesizes a novel view using a compute-adaptive renderer. Extensive experiments on RealEstate10K and DL3DV datasets quantitatively and qualitatively validate our approach, achieving significant data reduction with comparable rendering quality and the highest overall rendering score, while providing trade-offs of data size, rendering quality, and rendering speed.
Some detailed frame-level comparisons between DepthSplat and CLiFT with different compression ratios.






@article{Wang2025CLiFT,
author = {Wang, Zhengqing and Wu, Yuefan and Chen, Jiacheng and Zhang, Fuyang and Furukawa, Yasutaka},
title = {CLiFT: Compressive Light-Field Tokens for Compute Efficient and Adaptive Neural Rendering},
journal = {arXiv preprint arXiv:2507.08776},
year = {2025},
} CLiFT: Compressive Light-Field Tokens for Compute-Efficient and Adaptive Neural Rendering
CLiFT: Compressive Light-Field Tokens for Compute-Efficient and Adaptive Neural Rendering